Elasticsearch¶
This section describes the search for a high performance search analytics product which can sit between a foundation layer (RDBMS, filesystem) and application, and provide fast query performance, search capability, handle large volumes, fast ingestion, analytics, high availability etc.
Use Cases¶
MBD - DSPMBD-5030 * Three year projected merchant increase for transaction search performance -
Given a small merchant with 6,350 transactions processed over the last 365 days And a historic set of data existing to support up to 350k merchants When the merchant performs a transaction search for all their transactions over the course of a year Then the search returns the results in an average response of 3 seconds and 90% response of 5 seconds.
YMP - DSPYMP-5232 * Three year projected merchant increase for transaction search performance -
GIVEN a corporate merchant with X transactions processed over the last 365 days AND a historic set of data existing to support up to 950 merchants WHEN the merchant performs a transaction search for all their transactions over the course of a year THEN the search returns the results in an average response of 10 seconds and 90% response of 12 seconds.
Faster ingestion performance - At least 20k/s throughput for structured data ingestion, but ideally 100k/s or more. (The throughput is also dependent on size of row which is not accounted here but obviously we should see higher throughput for smaller row sizes, but 20k is the absolute minimum the system should meet)
Proposed architecture¶
This picture depicts where the product would sit within our existing architecture and interactions with other components:

Initial selection¶
With what we are after it’s unlikely a single product can satisfy all requirements, so it’s likely there will be trade-offs therefore we have widen the scope to include a variety of data technologies. Though I must mention with plethora of products available (see below) doing an initial selection was not easy.
Initial selection was based on product literature, white-papers, product specifications, and external agency ranking (Forrester and DB-Engines). This table shows high level requirement-features and if the product meets it:
| Product | Memory | Disk | cStore | Search | Scale | HA | XDCR | Lang | Rel |
|---|---|---|---|---|---|---|---|---|---|
| Solr | MMapFS | ✔ | Lucene | Hor | ✔ | ✔ | Java | 2004 | |
| Elastic | MMapFS | ✔ | Lucene | Hor | ✔ | ✔ | Java | 2004 | |
| Oracle | ✔ | ✔ | ✔ | Inverted | RAC | ✖ | ✔ | C | 1997 |
| PG CitusDB | ✖ | ✔ | ✔ | ✔ | Hor | ✔ | ✔ | C | 1996 |
| MariaDB | ✖ | ✔ | ✔ | ✖ | Hor | ✔ | ✔ | C | 2009 |
| MemSQL | ✔ | ✔ | ✔ | beta | Hor | ✔ | ✔ | C++ | 2013 |
| EXASOL | ✔ store | ✔ | ✖ | Hor | ✔ | ✔ | 2000 | ||
| Vertica | ✖ | ✔ | ✔ | ✖ | Hor | ✔ | ✔ | 2005 | |
| VoltDB | ✔ |
|
✖ | ✖ | Hor | ✔ | ✔ | Java | 2010 |
| Cassandra | ✖ | ✔ | ✖ | Hor | ✔ | ✔ | Java | 2008 | |
| Couchbase | ✔ | ✔ | ✔✔ | Hor | ✔ | ✔ | C++ | 2010 | |
| MongoDB | ✔ store | ✔ | ✔ | Hor |
|
✔ | C++ | 2009 | |
| Ignite(GG) | ✔ store | ✔ | Lucene | Hor | ✔ | ✔ | Java | 2007 | |
| GigaSpaces | ✔ | ✔ | Lucene | Hor | ✔ | ✔ | Java | 2000 | |
| Coherence |
|
✔ | Hor | ✔ | ✔ | Java | 2005 |
Product selection and evaluation¶
For the purpose of evaluation we have selected Solr, Elasticsearch, Apache Ignite, Oracle 12c In-Memory and MemSQL.
The selected products were tested on a single VM on GCP (4 vCPUs + 15GB RAM) with 100 million records. Oracle 12c In-Memory and MemSQL were tested on bigger machines with bigger volume.
Data role filter¶
How to enforce data role filter to searches on the ‘fast search’ product? There are various ways to do this and it ties up with the choice of tool:
- Relational Joins - If the data role filter and the transaction data stores are on the same database, then a join would be most appropriate in this case. - Oracle 12c In-Memory - MemSQL
- Distributed Joins - Join on the grid such as Apache Ignite. Colocated joins more performant than non-colocated. - Apache Ignite (GridGain)
- Client side push-down filter - The client constructs a list of data role filter (e.g. list of MIDs) using a query against a master data store, and then applies the list as filter to the second query against transactional data store. Both data stores can be same or entirely different technologies etc. The PoC should prove that we can run complex searches that also have a list of, say, 5000 MIDs added to the search criteria. - All tools
- Terms Lookup mechanism - Instead of specifying a filter with a lot of values it can be beneficial to fetch those values from a document in another index. - Elasticsearch
Decision analysis¶
Review and recommendation¶
Sorting¶
- Sorting (order by) is the biggest blocker for sub-second performance for pagination queries
- Apply filter to reduce the number of rows to 100K ideally or 1M max. (There is no way user is going to paginate through all the pages. Download is not real-time, need not be sorted, etc.)
- User can be shown the count and asked to apply more filter or reduce date range to bring it under the MAX allowed value.
- Or the application take the interim count and reduce the date range - assuming sorting is always and only on date transaction/processing column.
Coherence IMDG¶
- Already using Coherence for WPOS session tokens
- Next plan is to extend usage with Master data caching such as merchant and user details for WPOS
- We put Coherence to test by adding further use cases with increasing complexity
- Build our experience on IMDGs in terms of replication & partitioned caches, on-heap & off-heap memory, correct GC, managing several nodes, managing XDCR, nodes rebalancing, collocated and non-collocated queries, synchronisation, goldengate integration, etc.
- Going with other IMDGs - GG/Ignite, Hazlecast, JBoss Infinispan, Gigaspaces XAP - and storing and managing billions of rows at this moment is too risky, but we shouldn’t rule out for future based on our Coherence extension experience.
Oracle 12c In-Memory¶
- We don’t have In-Memory license
- In-memory performance was very good except when the range of input rows is huge (>100M) to sort (order by)
- In-memory columnstore is not first class citizen unlike other memory products where the data moves through memory to persistence layer. Oracle In-memory columnstore is seeded from disk.
MemSQL¶
- Good performance for billion of rows (MemSQL did a PoC with 26B rows)
- Very fast ingestion speed (> 100k/s)
- Data is stored ordered by index key. Reversing the order of index keys sort order results in very poor performance as it cannot use fast OrderedColumnstoreScan anymore.
- Queries which are not able to fan out to all nodes affects performance. (This should be seen with more testing to compare concurrent users using only one shard compared to concurrent fan-out queries using all shards - this could balance out itself.)
- Columnstore is built for sequential access, therefore random access on event-id has to be measured.
- It’s very likely that Corporate and SMEs will have different table design strategies. Performance issues can be seen for border merchants - like small corporates using SME table and vice-versa.
- Some query plan issues has been seen during PoC. Working with MemSQL on that.
- Some disk space increased usage during ingestion seen during PoC. Working with MemSQL on that.
Elasticsearch¶
- Good tool of choice in non-relational space focussed on searches.
- Certain aggregations are approximate - such as count distinct and percentiles aggregation. (therefore all aggregations output should be verified for reliability.)
- Aggregation performance should be evaluated.
- SQL query support coming soon - though applications doesn’t need it. Current query DSL is more than enough.
- Terms filter with join to another index to be evaluated for data role filter.
- Elastic support license cost?
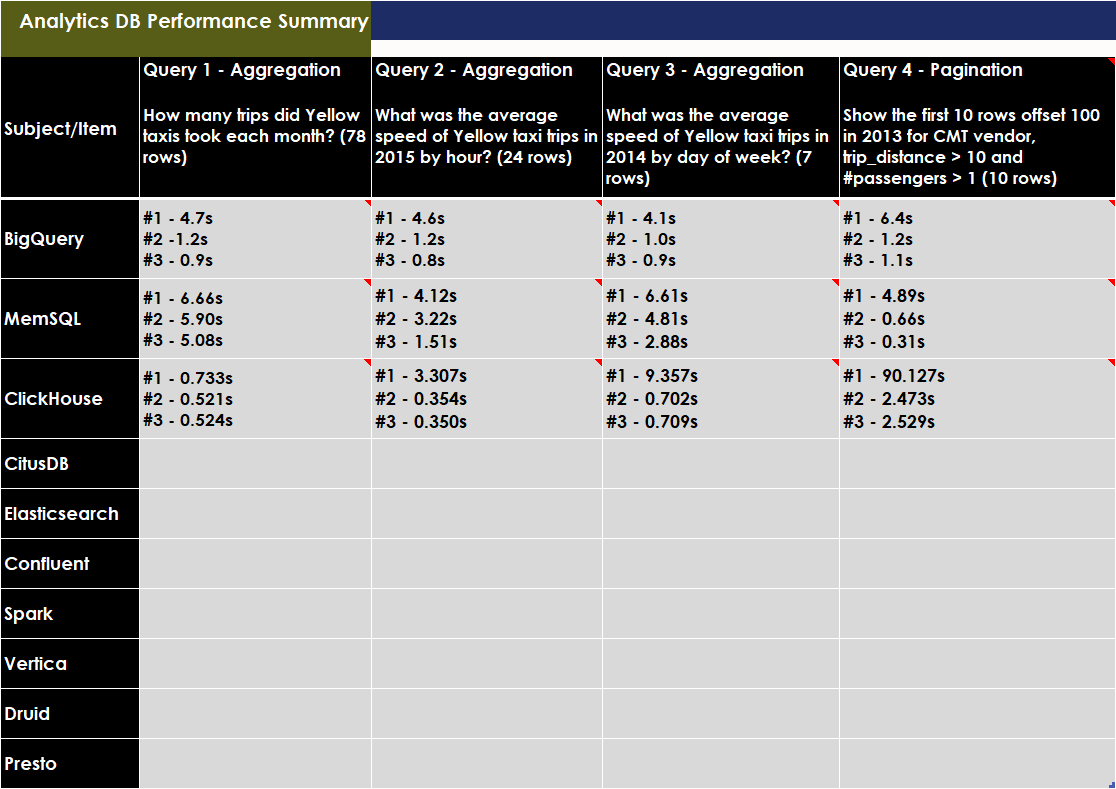
Performance test results¶
- MemSQL vs Elasticsearch
- 600M rows
- 12000 outlets
- 10 users with two having access to 5000 outlets, and a user each with access to 1000, 500, 100, 50, 10, 5, 2 and 1 outlet.
- 2 VMs - with 8vCPUs and 20-30GB RAM
- Both MemSQL and Elastic operating in cluster mode * MemSQL - 1 aggregator nodes and 3 leaf (data) nodes * Elastic - 2 nodes (master,data,ingestion) with 4 shards
- Set of 11 queries with mix of pagination, aggregation and lookup by event-id
- Each query ran twice for the same user (so consider buffer(hot)-disk(cold) and first time exceution plan creation, especially for MemSQL as it creates .so objects)
- Elastic didn’t used term lookup for data role filter, rather it used a simple range filter for outlets.







Proposed Architecture Diagram¶

- Possible use of Spark based ETL (Spark streaming, Spark SQL, etc.)
- Possible use of parquet file based Spark foundation data layer accessible through Spark SQL (shown as ? above)
- Possible use of Airflow as ETL workflow tool
Next steps¶
- Test MemSQL and Elasticsearch on PROD sized infrastructure and data volumes and run all performance tests
- Design and provision infrastructure on cloud or on-prem
- Use data generator or PPE data
- Use existing performance test pack (would need to change to adapt to SQLs and Elastic APIs)
- Put together a team for above activities with representation from SA, Infra, Dev, BA, Test, etc.
- Get business, Infra, Support buy-in for above